
Power Grid Scenarios

Our team utilized the ELSA Cluster Computing Hardware running MATLAB to simulate and analyze the behavior of the TCNJ power grid under a wide range of distressed and emergency scenarios, such as the failure of specific lines, switches, or generators. The project’s objectives include identifying system vulnerabilities, evaluating grid reliability and sustainability, and determining the optimal locations for additional generation and energy storage resources. To accomplish this, we adapted traditional line and load models from textbook examples to mirror the topology and scale of TCNJ’s actual power grid. Through these simulations, we aim to better understand how the campus grid would respond to real-world disruptions and infrastructure upgrades.
The ELSA Cluster was essential to this work. Our simulations involved double contingency analysis, which required modeling steady-state voltages for all buses across every possible combination of two independent outages. With the number of potential failures denoted by N, this analysis scales exponentially to 2^N scenarios. This is well beyond the capabilities of a standard PC. The parallel computing architecture of ELSA allowed us to run these simulations efficiently and at scale, making this critical reliability assessment feasible.
Galaxy Simulation

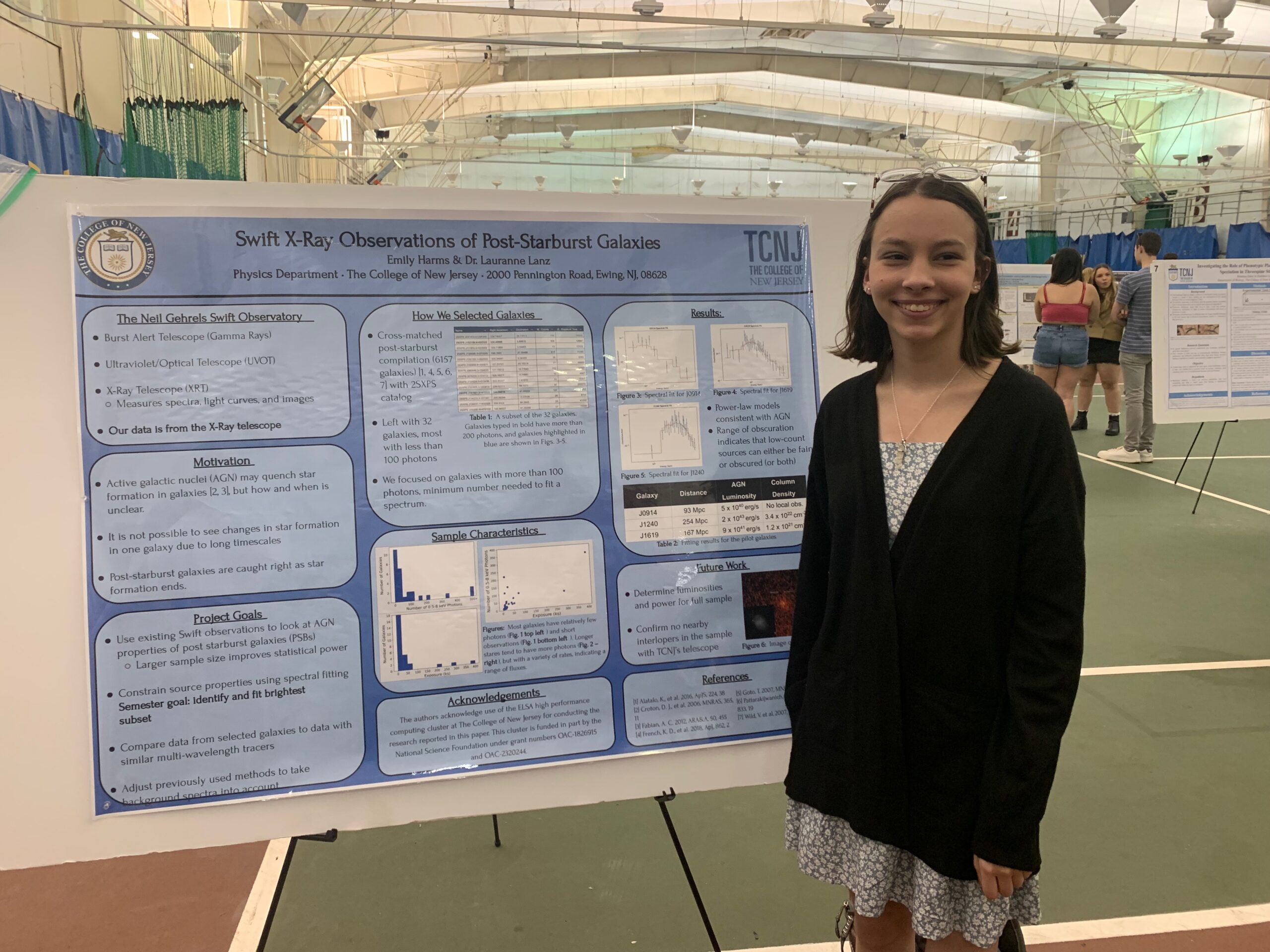
Student researchers from Dr. Lauranne Lanz’s lab
Almost all information about the Universe beyond our solar system is learned from analyzing images and spectra. This requires writing Python code and using specialized software to prepare these images and extract the information that will enable us to make conclusions about the physics of the galaxies and their black holes. The large number of images and galaxies we work with means that having ELSA is crucial to accomplishing this task in a reasonable amount of time.
How galaxies change over the lifetime (past and future) of the Universe is still poorly understood: they initially grow through the formation of new stars out of gas and dust, but this eventually stops. How this change happens and what role is played by activity from the central supermassive black hole are two of the largest questions in astronomy. Our group studies the supermassive black holes in the centers of galaxies caught right as they stop forming stars to investigate the nature and activity of these black holes and their galaxies. We also take new observations with our campus 0.7m research telescope to get more detailed images when needed.
Life in Moving Fluids
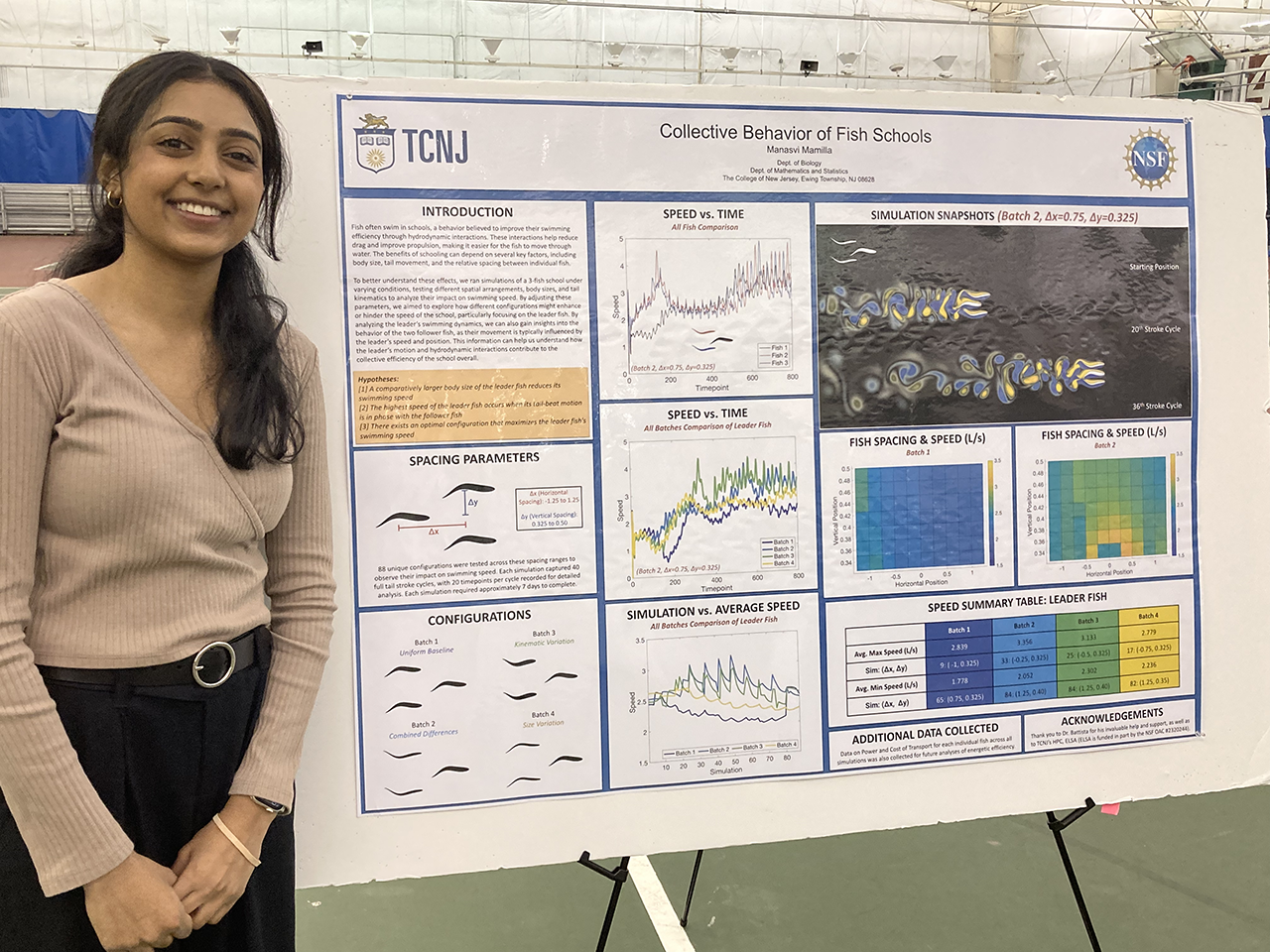
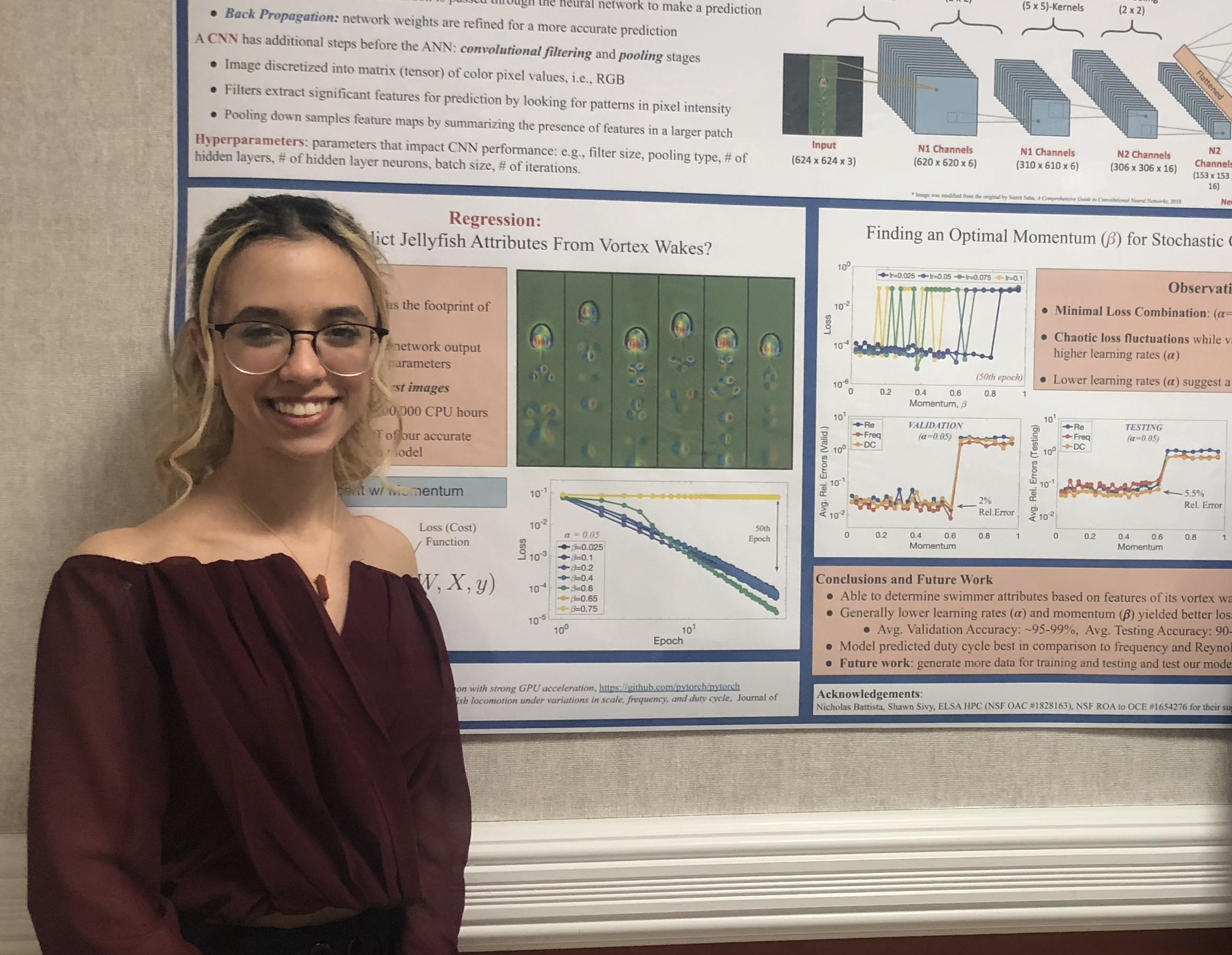
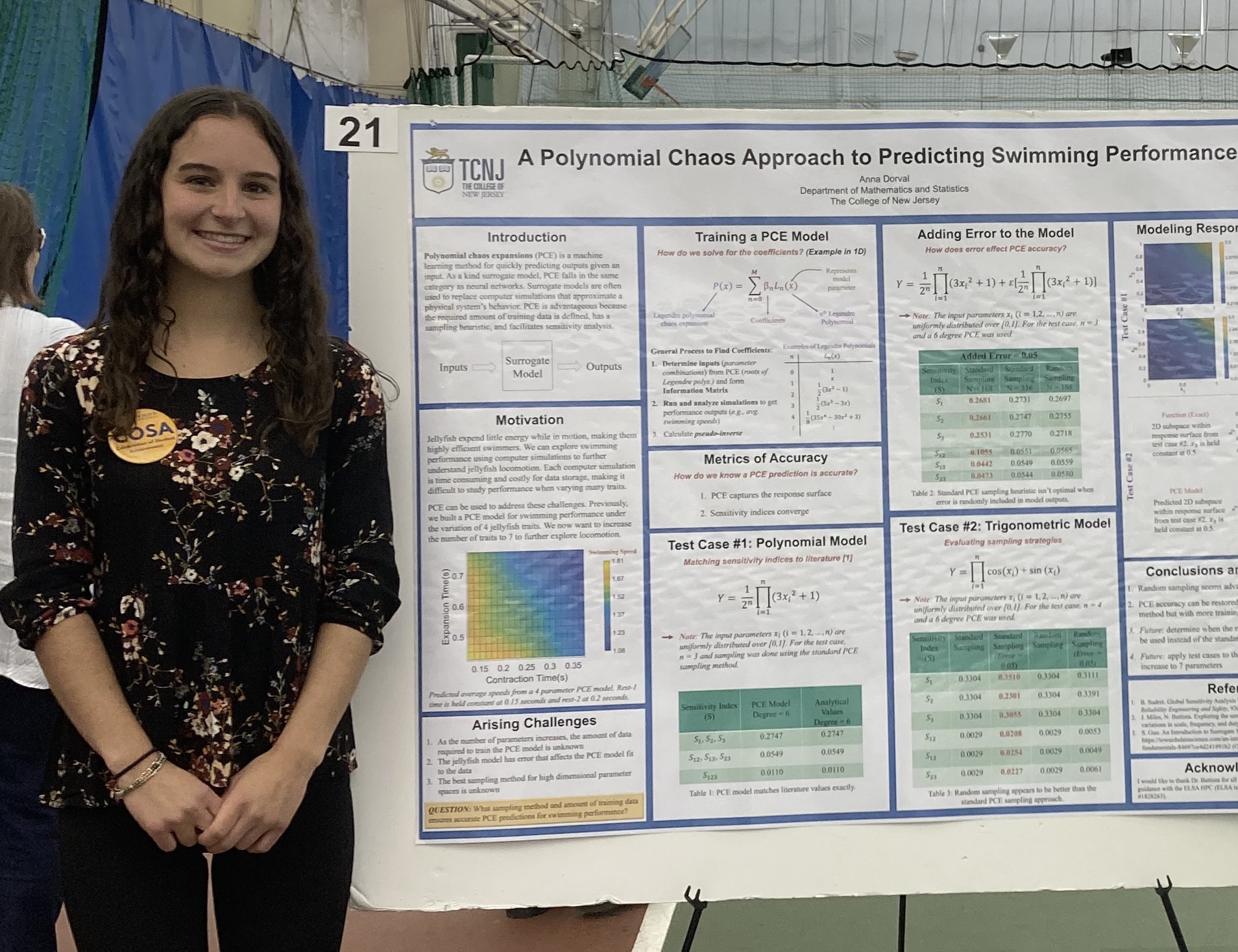
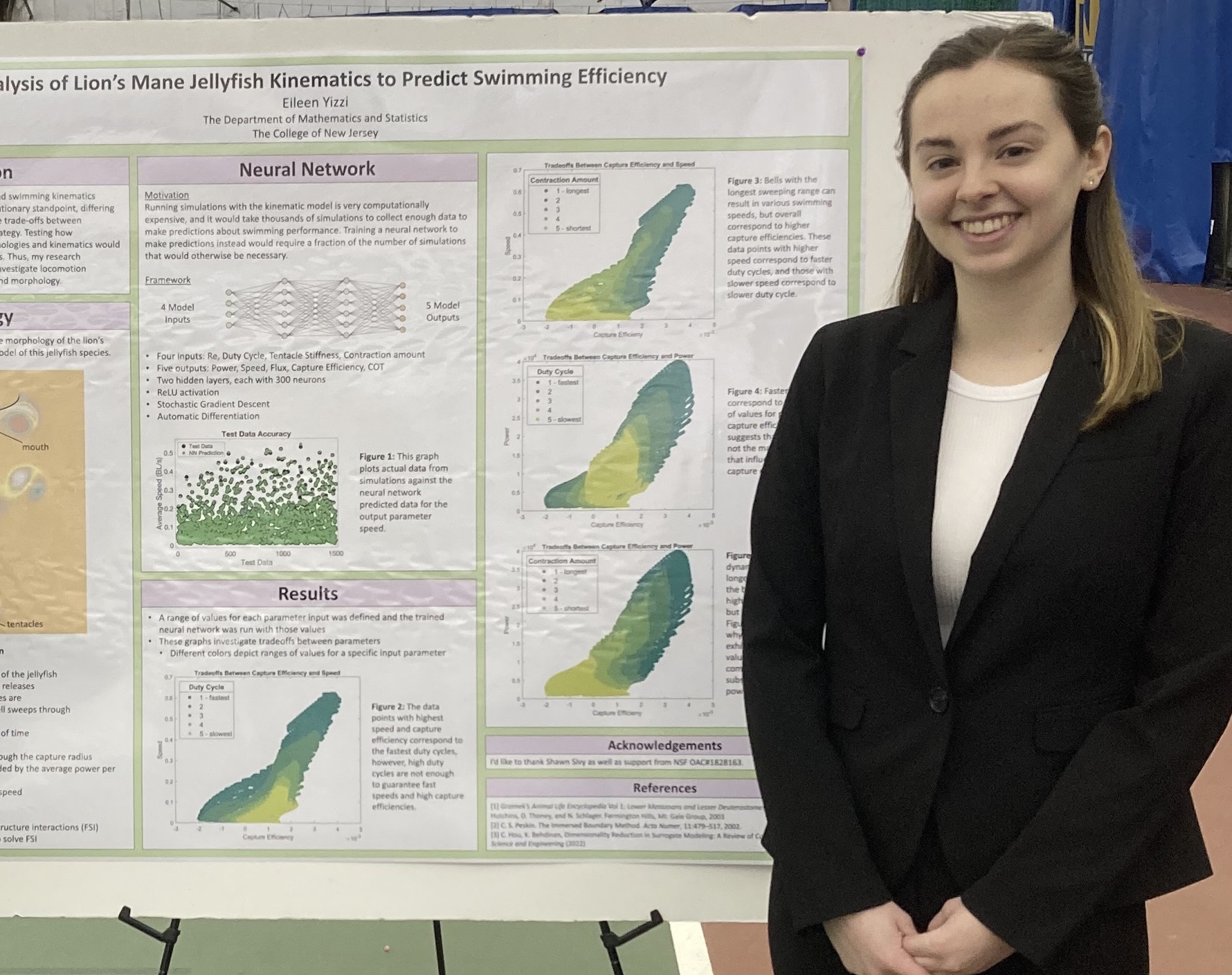
Student researchers from Dr. Nick Battista‘s lab
Our lab explores life in moving fluids, using physics-based computer models to reveal the mechanics of swimming, flying, and other forms of motion. By blending mathematics, engineering, and biology, our work uncovers the fundamental rules that govern movement and energy use in nature. These insights not only deepen our understanding of the living world but also inspire innovations in technology, from efficient underwater vehicles to bio-inspired robotics.
Our work hinges upon access to high-performance computing. We routinely leverage the parallel processing power of HPC and perform thousands of high-fidelity numerical simulations to collect data to train our machine learning models. This allows us to holistically explore how different traits affect performance in a number of organisms and perform novel analyses that otherwise would be impossible to perform. Students learn how to create and validate computational fluid dynamics models, refine their programming skills, analyze massive datasets, and visualize scientific data, as well as develop, train, and validate machine learning models.
Pattern Formation & Synchronization
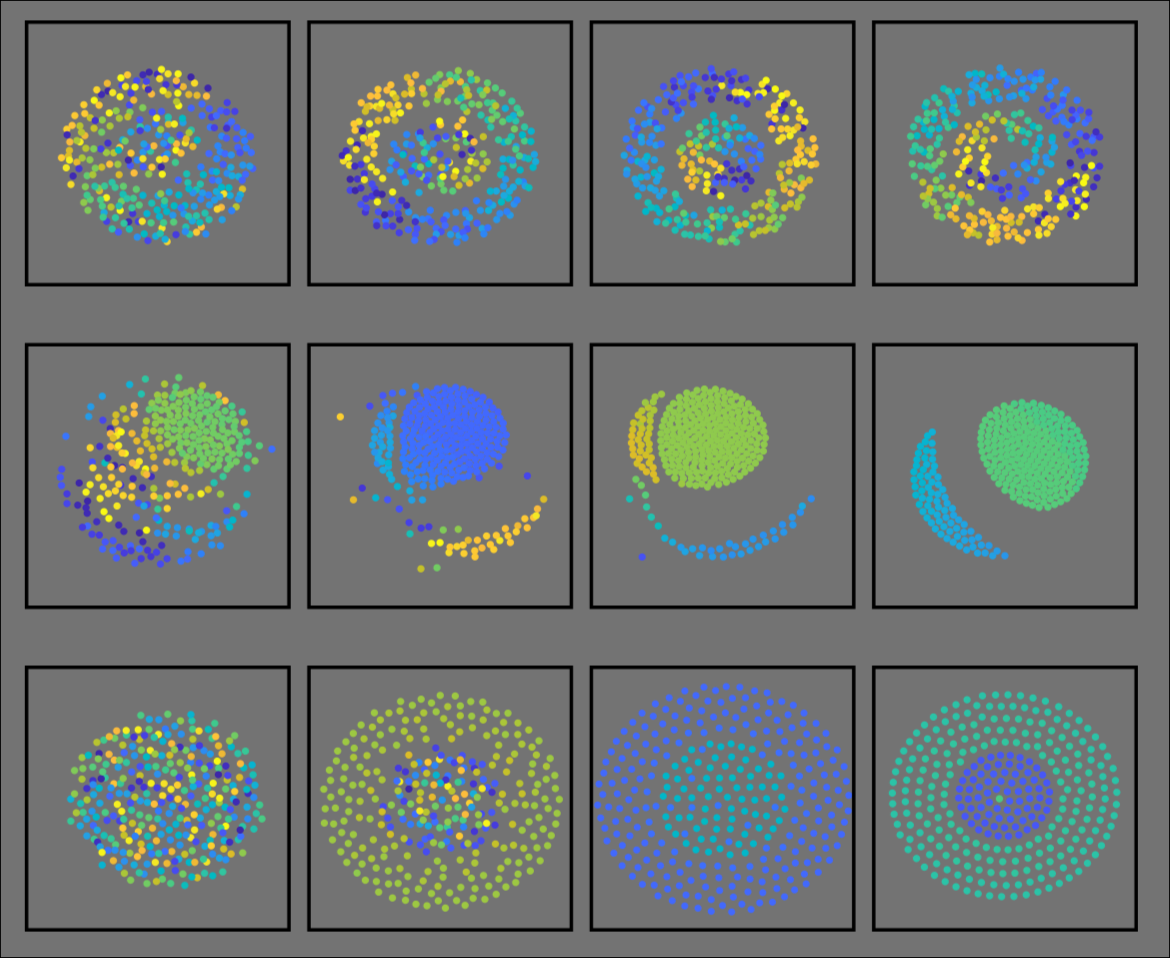

Student researchers from Dr. Matthew Mizuhara‘s lab
Our group studies pattern formation and synchronization in systems of many interacting agents. Such systems are quite ubiquitous in the real world: our projects have ranged from the study of coupled oscillator systems to the dynamics of math anxiety in classrooms. By leveraging both theoretical mathematical techniques together with numerical simulations, our research helps provide insights into both the mechanisms underlying emergent patterns from individual interactions, as well as how changing these mechanisms can affect the long-time behaviors.
The mathematical models of synchronizing systems involve large numbers of complex equations, which are impossible to solve by hand, and are often impractical to solve on personal computers. As such, we require large-scale simulations to solve these equations, visualize the results, and compare behaviors across many different biophysical parameters. Students learn mathematical modeling and theory, how to numerically solve mathematical models, data management, and how to generate mathematical conjectures from data.
Molecular Modeling





Student researchers from Dr. Joe Baker’s lab
Our research group uses powerful supercomputers to understand how life works at the molecular level. We create detailed virtual models of the tiny “hairs” bacteria use to cause infections, aiming to discover new ways to block this process and develop novel medicines. We also explore the powerful adhesive proteins in barnacle glue and structural proteins within barnacle shells, which can teach us how to design new materials and understand how marine organisms are affected by climate change. By studying these fundamental biological systems, we hope to solve pressing challenges in both medicine and materials science.
Data and computing are absolutely essential to our work, as we rely on supercomputers to simulate the complex movements of molecules in a way we couldn’t otherwise observe. Students working on these projects develop a unique and powerful skillset at the intersection of biology, chemistry, physics, and computer science, learning to code, analyze massive datasets, and model complex systems.
Data Science
My broad research agenda can be characterized by the goal of identifying and assessing the mechanisms through which organizational policies create and/or maintain inequality. In one project, I examine the impact of choice-based social service systems on inequality in the United States. For example, we use data from the National Rent Project to examine the impact of anti-discrimination law on text in Craigslist listings. In another, we examine the impact of organizational policy for Science, Technology, Engineering, and Mathematics (STEM) on student outcomes.
High-performance computing and data analysis are essential to this work, as many projects involve cleaning and analyzing large-scale administrative datasets, text data, building statistical models, and creating interactive visualizations and dashboards. Students gain experience in R programming, statistical inference, and data visualization, while also learning to communicate findings to both technical and non-technical audiences. These skills prepare them to tackle complex, data-intensive problems across academia, policy, and industry.
Mathematical Models of Cancer Progression
Our research group develops data-driven mathematical models of cancer progression and treatment response. We use these models to inform experimental design and to make experimentally testable biological predictions. Our aim is to improve understanding of why different patients with the same cancer diagnosis can respond so differently to the same therapeutic modality.
While I tend to study simple mathematical models, the process of fitting models to data, analyzing the sensitivity to model structure and parameters, and running simulation experiments is computationally very intensive. We regularly leverage the parallel processing power of the HPC to drastically speed up the time it takes to run our computational experiments. Students learn mathematical modeling, algorithm development, data management/analysis/visualization, and interpreting results in a real-world context.
Molecular Biomimetics

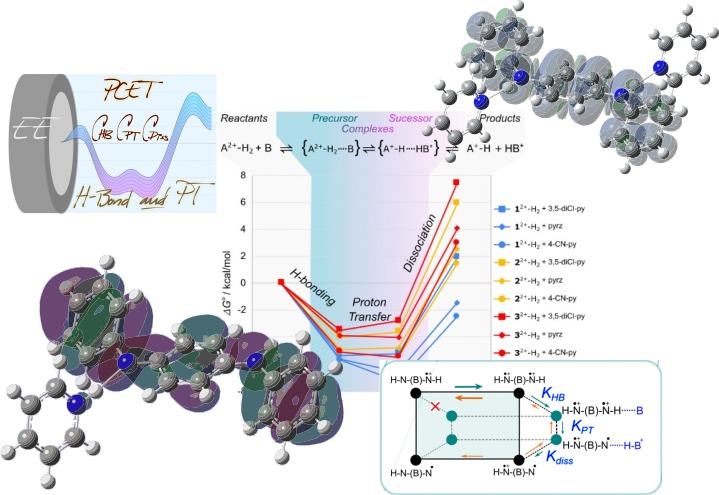

Student researchers from Dr. Giovanny Parada‘s lab
We study how biological systems use hydrogen—the universe’s smallest and most abundant atom—to build complex molecules with very little wasted energy. By splitting hydrogen into its charged components, a positive proton and a negative electron, nature allows them to move independently. The challenge lies in managing the delicate balance between this freedom of movement and the powerful attraction that pulls these opposite charges back together.
The molecules we study, while small and simple in their chemical structure, require computational methods to estimate their energies upon moving a proton and an electron. The calculated estimates are used to validate our experimental data.
Changing Environments


Student researchers from Dr. Matthew Wund’s lab
Our research group studies how animals respond to changing environments, both from the perspective of individuals adapting to their surroundings within their own lifetimes, as well as whole species evolving over successive generations via evolution by natural selection. We use the threespine stickleback fish (Gasterosteus aculeatus) as a model system to address our questions, because sticklebacks are renowned for their ability to adapt and thrive in a variety of freshwater and marine environments. Over the years, our projects have focused on how stickleback develop and evolve when new predators are introduced to their habitats, and when marine stickleback colonize newly available freshwater habitats. Our current project is investigating the early stages of the formation of new species in three freshwater populations that are in the process of being established by marine immigrants.
Our experiments and field studies generate a lot of data, including many high-resolution photographs and video files in addition to numerical data. The high-performance computing cluster provides essential storage to safely organize and archive this data. Through their interactions with the cluster, my research students learn good habits of data management.
Exoplanets
My group explores the formation and evolution of exoplanets (planets outside of the Solar System), particularly through the lens of habitability. We explore this exclusively through computer simulations of real systems to find the planet properties (like composition) and through millions of fake systems. We aim to both learn about known planets and to constrain formation conditions when the Solar System formed.
Our work is entirely computational. Students learn to process and reduce data, to code and run simulations, and to statistically explore planets as individuals and as a group. For datasets with tens of dimensions, we also use various machine learning techniques to process and learn from the data.
Imputation Methods
I am relying on the ELSA Computing Cluster for an examination of missing data imputation performance across a variety of imputation methods, but principally high-dimensional ensemble classifiers such as random forest. The Computing Cluster can cut down on computational time considerably over interactive approaches, especially with random forest imputation. I am particularly interested in how random forest imputation performs relative to other imputation methods in recovering the data-generating process of simulated data subject to various missing data mechanisms imposed on the data, with a particular emphasis on contributions from group-level effects. An application of this methodology can be applied to panel studies across multiple different settings, such as high schools, and among self-report data from students in those high schools
I hope to bring students in statistics, applied mathematics, and computer science into this computational project this coming academic year. There are many possibilities here for exploration in computational data science, statistical analysis, and inference.
Mathematical Models in Biological Sciences
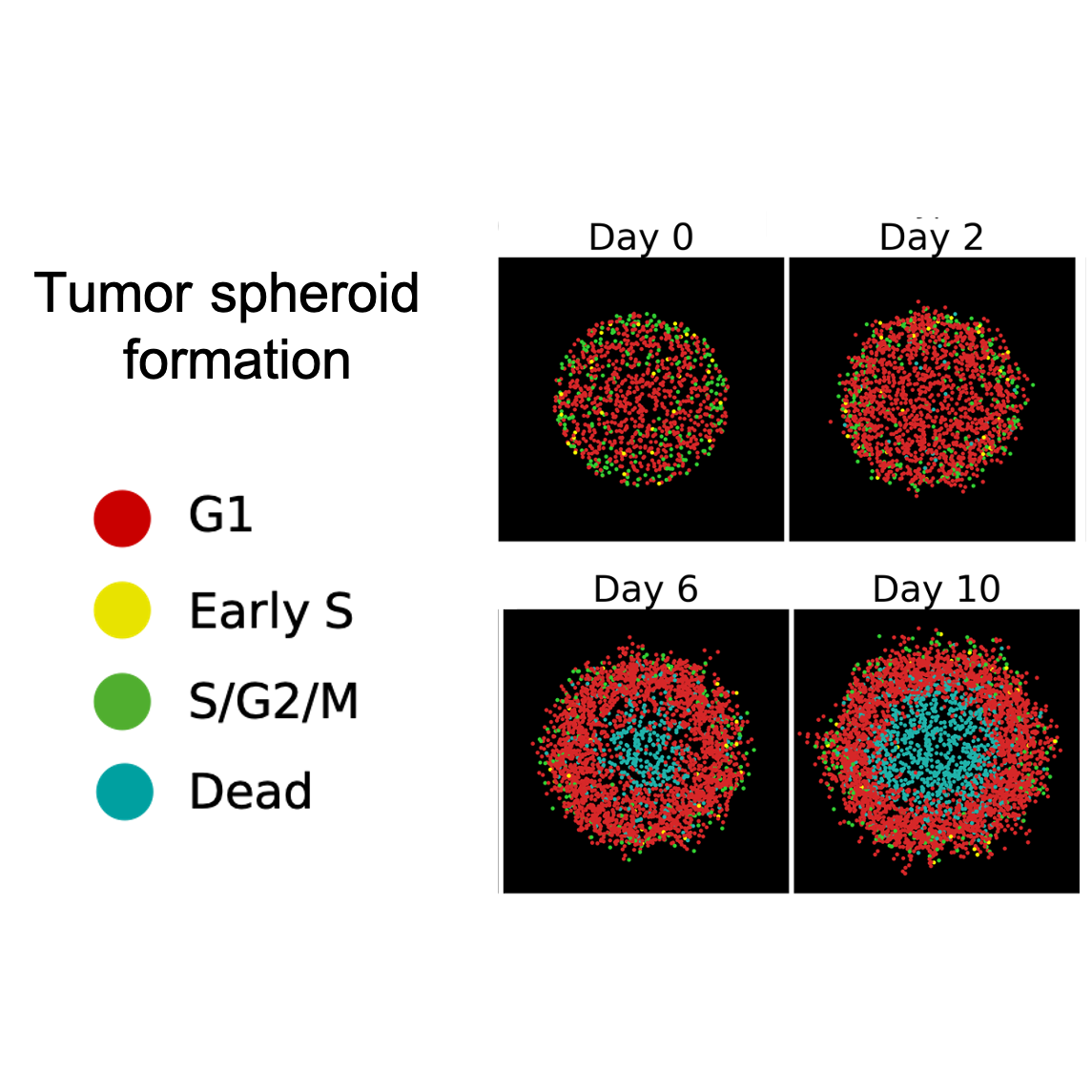
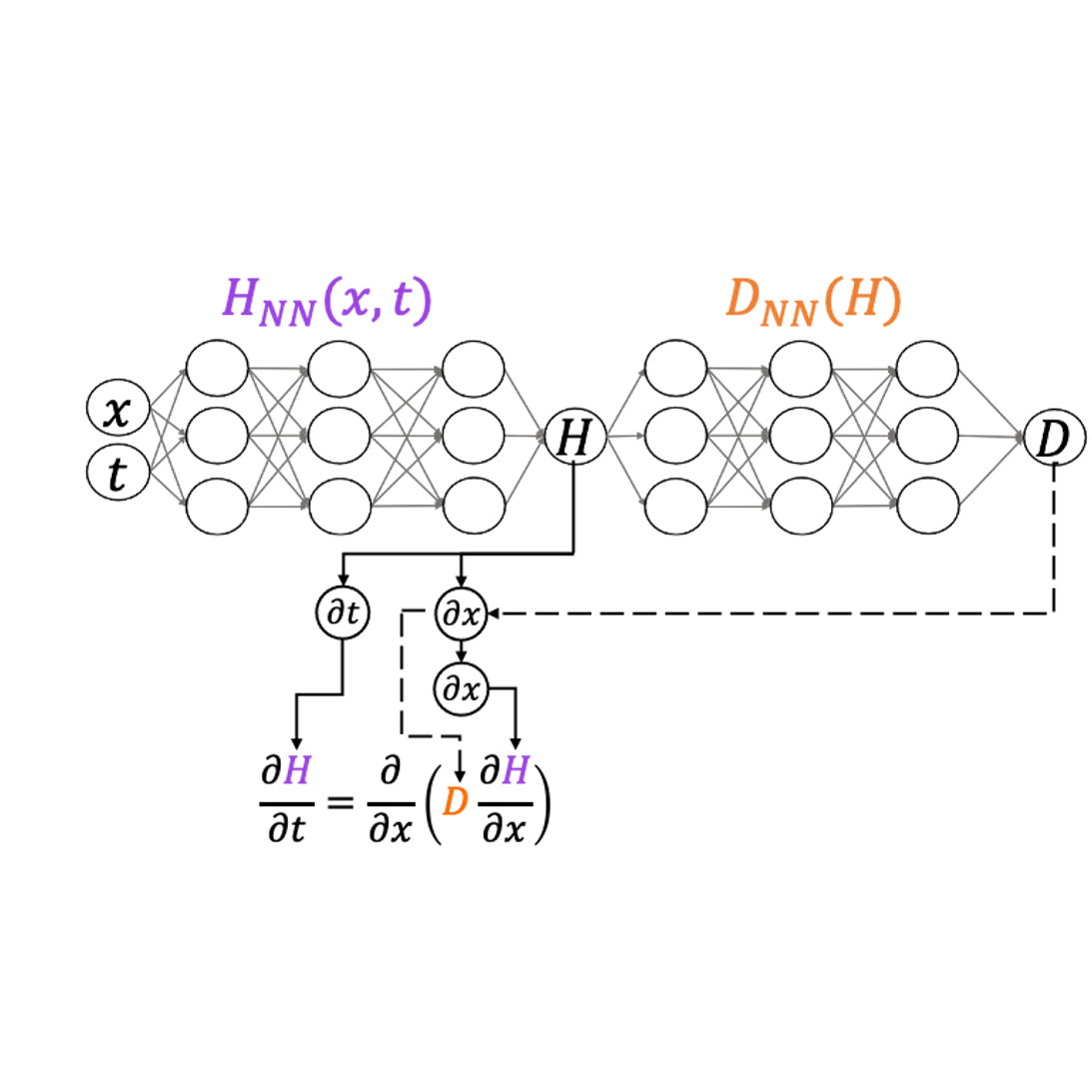
Research from Dr. John Nardini
Mathematical models are now a crucial part of the biological sciences. Models of biological phenomena can serve as time- and financially-efficient approaches to determine the most effective future experiments to perform, or they can generate new hypotheses to be tested. Despite the importance of modeling, it is a challenging process! We develop computational methods to efficiently connect mathematical models to biological data. These methods often involve machine learning, and they are often applied to models of cell biology, including wound healing and tumorigenesis.
Our work requires many simulations of mathematical models as well as the training of sophisticated machine learning-based models. As such, we often leverage the HPC to perform numerous simulations in parallel to infer the range of possible model outputs and compare them all to biological datasets. On the machine learning side, we need to train our large model to imitate a large dataset, which often requires the use of GPUs present on the HPC.